
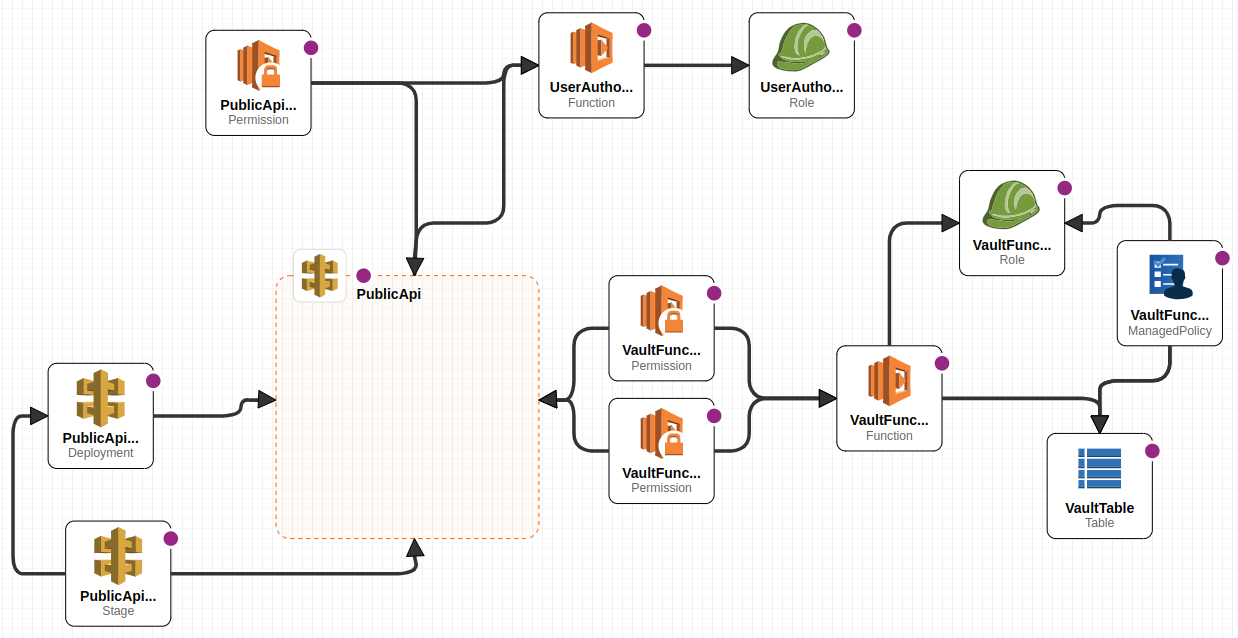
This is the 5th installment of Information Vault. In this one there is working code for storing Private data Metadata and removing it from the vault. Also authorization to use the API Gateway has been added with a custom Lambda. There are test cases to validate the ownership of data and authorization of requests is now made against a hardcoded list of users. All the code can be found on.
https://github.com/mtzmontiel/dip-data-vault
Continue reading for code snippets and details.
Let’s focus on authorization with AWS API Gateway, for this I’ll be mocking part of the flow as this is a simple example but it will help understand how this can be used in a production ready environment.
The first important decision regards to the identifier assigned to each principal, for this example I’ll be using a finite enumeration of 2 users, but will not use those as the authentication mechanism. For that I’ll be using JWT but as authentication is outside of the scope I will be providing those outside of the flow hence only the authorization will rely on the JWT being correct. This is not meant for a real environment, just for an exercise like this one. From that JWT the principal Identification can be extracted and allow both API Gateway and worker lambda to know who is interacting with the system.
principals = dict()
principals['aid1'] = dict()
principals['aid1']['principal'] = "user1"
principals['aid2'] = dict()
principals['aid2']['principal'] = "user2"
Modify test to provide a JWT for current tests, currently it will be passed through environment variables to the test case. Even with this change the 2 test cases should be green as no change in backend has been made.
def test_api_gateway_store(self, api_gateway_url, user1_auth):
""" Call the API Gateway endpoint and check the response """
response = requests.post(api_gateway_url,
headers={"Authentication":user1_auth},
json={ # more lines elided
And the removal test case.
def test_api_gateway_remove(self, api_gateway_url, user1_auth):
""" Call the API Gateway endpoint and check the response """
data_tokens = self.invoke_store_data(api_gateway_url, "givenname", "givenname", "name", user1_auth)
# some lines elided
response = requests.patch(api_gateway_url,
headers={"Authentication":user1_auth},
json={ # more lines elided
Add test a new case: disallow removal of not owned tokens. This one will fail as there is no validation going on on the backend and actually, the backend is only doing echo back from the initial call.
def test_api_gateway_remove_with_different_user(self, api_gateway_url, user1_auth, user2_auth):
""" Call the API Gateway endpoint and check the response """
data_tokens = self.invoke_store_data(api_gateway_url, "givenname", "givenname", "name", user1_auth)
data_element = validate_alias_in_data_elements(data_tokens, "givenname")
token = validate_token_in_element(data_element)
response = requests.patch(api_gateway_url,
headers={"Authentication":user2_auth},
json={
"elements": {
"givenname": token}})
assert response.status_code == 403, f"Response: {response.content}"
body = response.json()
assert "error" in body, f"Body: {body}"
assert body["error"] == "Forbidden"
To be able to do something else besides echoing the request on the response, we need storage where we can put the values, the vault. On this vault besides the original Private Data we need to add something to know who is the owner and we can use the principal id for that matter. With this we then can validate if the Remove Private Data request can be performed over a given Token.
Here is where the decision to partition Tokens at Owner will become hardened. Depending on how the data is stored it means how easy it would be to do the validation. Going with DynamoDb means we need to define a PartitionKey which needs to have something from the Owner and something unique for the token. We can structure like this:
PD#{owner}#{token}
This definition is very simple for this particular exercise and can potentially be extended for other usages like adding metadata. The attributes that are also added to the Item will be the Owner, Token, EncryptedData(on next iterations), CreatedAt, RemovedAt(once we update the Remove Data handler).
Update worker to handle state is a little more involved so it will be done in steps. First adding storage as a DynamoDb with minimal definitions so in the initialization code of the lambda we obtain the boto client for the DynamoDb table.
def create_table(table_name):
return boto3.resource('dynamodb').Table(table_name)
Then granting the Worker lambda permissions to write and read from it using SAM Connector which is the simplest way to allow these operations.
VaultTable:
Type: AWS::Serverless::SimpleTable
Properties:
PrimaryKey:
Name: pk
Type: String
# Not setting ProvisionedThroughput as this is a test and we do not expect load.
# This could be different in a real world scenario.
VaultFunction:
Type: AWS::Serverless::Function
Connectors:
MyTableConn:
Properties:
Destination:
Id: VaultTable
Permissions:
- Read
- Write
Properties:
CodeUri: data_vault/
Handler: owner.lambda_handler
Runtime: python3.11
Environment:
Variables:
# This is the DynamoDB table name
TABLE_NAME:
Ref: VaultTable
Now to obtain the principal id from the request it is very simple with AWS API Gateway invocation to Lambda. The part where it will be mocked will be on a different lambda used as an authorizer.
def extract_principal_id(event):
return event["requestContext"]["authorizer"]["principalId"]
Create a new Lambda function on the SAM template.
UserAuthorizerFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: authorizer/
Handler: authorizer.authorizer_handler
Runtime: python3.11
Architectures:
- x86_64
Now to add the authorization we need to declare the API as previously it was using an implied API but this requires an explicit declaration.
PublicApi:
Type: AWS::Serverless::Api
Properties:
StageName: Prod
Auth:
Authorizers:
UserAuth:
FunctionArn: !GetAtt UserAuthorizerFunction.Arn
FunctionPayloadType: REQUEST
Identity:
Headers:
- authorization
DefaultAuthorizer: UserAuth
Then the event mappings need a reference to the explicit API so it now becomes.
Events:
DataStore:
Type: Api
Properties:
Path: /
Method: post
RestApiId:
Ref: PublicApi
DataRemove:
Type: Api
Properties:
Path: /
Method: patch
RestApiId:
Ref: PublicApi
On the authorizer lambda we need to retrieve the principal id from the JWT and create a policy that is used by API Gateway to allow or disallow execution. Here I’ll be restricting just a couple of values as this is a mock implementation. In a real life scenario this would connect to your IAM services or UserPool to validate the Authentication and provide the context if the validation is successful.
def authorizer_handler(event, context):
print(event)
principal_id = extract_principal_from_jwt(event['headers']['Authorization'])
if principal_id is None:
return deny_policy(event)
policy = allow_policy(event, principal_id)
print(policy)
return policy
def deny_policy(event):
return generate_policy('user', 'Deny', event['methodArn'])
def allow_policy(event, principal_id):
return generate_policy(principal_id, 'Allow', event['methodArn'])
When generating the policy all resources and methods that a given user can invoke need to be added as the result of the invocation to this lambda will potentially be cached by AWS API Gateway depending on the configuration. This is done in the following block.
def generate_policy(principal_id, effect, arn):
auth_response = {}
auth_response['principalId'] = principal_id
if effect and arn:
tmp = arn.split(':')
apiGatewayArnTmp = tmp[5].split('/')
awsAccountId = tmp[4]
regionId = tmp[3]
restApiId = apiGatewayArnTmp[0]
stage = apiGatewayArnTmp[1]
# method = apiGatewayArnTmp[2] not used for this example
policy_document = {}
policy_document['Version'] = '2012-10-17'
policy_document['Statement'] = []
for httpVerb in ["POST","PATCH"]:
resource = f"arn:aws:execute-api:{regionId}:{awsAccountId}:{restApiId}/{stage}/{httpVerb}/"
statement_one = {}
statement_one['Action'] = 'execute-api:Invoke'
statement_one['Effect'] = effect
statement_one['Resource'] = resource
policy_document['Statement'].append(statement_one)
auth_response['policyDocument'] = policy_document
return auth_response
Now to the worker lambda code we must add the storing and delete from the DynamoTable. While doing this update I became aware that the Removal of Private data handling multiple tokens on a single call would overtly complicate the response handling both on server on client side so I decided to allow only a single token per patch call. I’m now tempted to convert it to an HTTP DELETE but will keep this for now.
Store an Item on the Data Vault table is simple.
def store_data(event, context):
"""Store Private data and respond with corresponding tokens"""
elements = extract_elements(event)
results = dict()
principal_id = extract_principal_id(event)
for k,v in elements.items():
token = tokenize(v)
ddresult = table.put_item(Item={
"pk": get_pk(principal_id, token),
"owned_by":principal_id,
"token": token,
# NOT STORING RIGHT NOW AS IT IS UNSAFE. Right? :)
# "value": v
})
if ddresult["ResponseMetadata"]["HTTPStatusCode"] != 200:
results[k] = dict()
results[k]["success"] = False
continue
results[k] = dict()
results[k]["token"] = token
results[k]["success"] = True
return results
And the simple removal is done with this code. With the Partition Key (pk) that was defined above would have been sufficient to do the validation of ownership but if that PK is to be changed later I added the ConditionExpression to only delete the Item when owned_by equals the principal doing the invocation.
def remove_data(event, context):
"""Remove private data by tokens"""
principal_id = extract_principal_id(event)
results = dict()
token = extract_token(event)
results["token"] = token
try:
ddresult = table.delete_item(Key={"pk": get_pk(principal_id, token)},
ConditionExpression="owned_by = :val",
ExpressionAttributeValues={":val": principal_id})
if ddresult["ResponseMetadata"]["HTTPStatusCode"] != 200:
results["success"] = False
results["message"] = "Could not process request."
else:
results["success"] = True
results["message"] = "Successfully Removed"
except res.meta.client.exceptions.ConditionalCheckFailedException as e:
results["success"] = False
results["message"] = "Could not process request"
return results, e
return results, None