
In the previous posts I wrote about the design for an information vault as described in John Crickett Coding Challenges, in those I decided to implement it somehow differently but the concept remains the same. In this post there is actual Code! And also it was done in a Behavior Driven Development kind of way, meaning that the tests got written before the implementation.
Technology wise this will be done on AWS with a couple API Gateways each for the different flows and a single backing lambda. For storage DynamoDB will be used and for encryption Amazon Key Management Service will be used.
Continue reading for diagrams and code snippets.

So for starters, the two public facing operations are “Store private data” and “Remove private data”, I’ll map them to an HTTP Post and an HTTP Patch as both requests can have many data elements to process. In the future an HTTP Delete with a single item would be trivial to implement.
While implementing the test cases I became aware that there were inconsistencies in my Payload Definitions by mixing dataElements, dataTokens, results and tokens which all are just containers. Going forward those will be only elements both in requests and responses. All APIs should be predictable and payloads should follow a similar structure to avoid weird bugs.
The test case for Store has the following high level structure, post a request to the API with a known payload, then validate the HTTP response code. Afterwards comes the payload structure validation. Fortunately python requests and json modules already do a lot of heavy lifting, if the payload is not well structured the test case will fail. Current implementation only checks for existence of attributes but it will be expanded later. Also it is important to note that this call is currently unauthenticated as no credentials or authorization is being passed on the request.
def test_api_gateway_store(self, api_gateway_url):
""" Call the API Gateway endpoint and check the response """
response = requests.post(api_gateway_url, json={
"elements": {
"givenname":{
"value":"my name", "classification":"name"},
"contact1":{
"value":"email@other.com", "classification":"email"},
"phone1":{
"value":"+521234567890", "classification":"phone"}}})
assert response.status_code == 200
body = response.json()
given_name = validate_alias_in_body_data_elements(body, "elements", "givenname")
validate_token_in_element(given_name)
contact = validate_alias_in_body_data_elements(body, "elements", "contact1")
validate_token_in_element(contact)
For the removal of private data the test case is very similar to the creation but it has to chain a call to store first and then a remove. This is to make the tests idempotent and not to have to rely on prior state. After storing private data a new token will be generated and with that token the remove request is created. The final check is to have the token and expected result in the data element.
def test_api_gateway_remove(self, api_gateway_url):
""" Call the API Gateway endpoint and check the response """
data_tokens = self.invoke_store_data(api_gateway_url, "givenname", "givenname", "name")
data_element = validate_alias_in_data_elements(data_tokens, "givenname")
token = validate_token_in_element(data_element)
response = requests.patch(api_gateway_url, json={
"elements": {
"givenname": token}})
assert response.status_code == 200, f"Response: {response.content}"
body = response.json()
data_element = validate_alias_in_body_data_elements(body,'elements', "givenname")
assert "success" in data_element, f"Data element: {data_element}"
assert data_element["success"] == True
Now for the server side of this implementation, I’ll be using the Serverless Application Model to define a Python Lambda that will handle both requests. Here I’m mapping the location of my code on the folder structure, defining the runtime to use and also using the transformations that SAM has to define the event source for the lambda which in turn will result in the creation of an API Gateway.
Resources:
VaultFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: data_vault/
Handler: owner.lambda_handler
Runtime: python3.11
Architectures:
- x86_64
Events:
DataStore:
Type: Api
Properties:
Path: /
Method: post
DataRemove:
Type: Api
Properties:
Path: /
Method: patch
The folder structure for the project currently has on root folder the template definition for SAM and separate folders for tests and for production code.
As this is being developed with BDD in mind, I’ll deploy a minimal API and lambda that create the infrastructure but fail the tests.
def lambda_handler(event, context):
return {"statusCode": 500, "body": f"Unimplemented Yet!"}
To deploy using SAM it is pretty straightforward using
~/projects/dip-data-vault$ sam deploy --guided
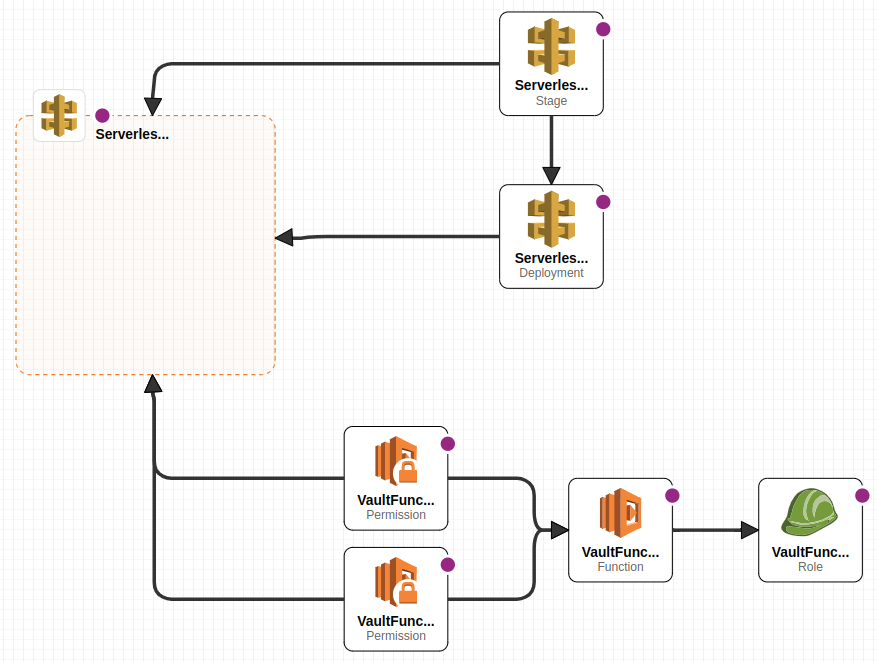
This creates the following stack on AWS which has the serverless VaultFunction and the IAM Role for it, the Serverless API Gateway, a Stage and a Deployment of said Serverless API Gateway. It also creates the permissions for API Gateway to invoke the Vault Function.
This deployment does not allow the test case to pass so adding the sufficient code for it to work, even if not actually creating tokens or being secure, will be the next step. To store data it is only necessary to return the results over the same key but with name token instead of value.
def store_data(event, context):
"""Store Private data and respond with corresponding tokens"""
elements = extract_elements(event)
results = dict()
for k,v in elements.items():
results[k] = dict()
results[k]["token"] = v["value"]
results[k]["success"] = True
return results
While for Private Data Removal it is very similar but transformation is much simpler if we are only doing mock implementation.
def remove_data(event, context):
"""Remove private data by tokens"""
elements = extract_elements(event)
results = dict()
for k,v in elements.items():
results[k] = dict()
results[k]["token"] = v
results[k]["success"] = True
return results
This will pass the test cases, so let’s do that by updating the stack and running the tests.
~/projects/dip-data-vault$ python -m pytest tests/integration -v
============================= test session starts =======================
platform linux -- Python 3.10.12, pytest-8.0.2, pluggy-1.4.0 --
cachedir: .pytest_cache
rootdir: /home/rafael/projects/dip-data-vault
collected 2 items
tests/integration/test_owner_api_gateway.py::TestApiGateway::test_api_gateway_store PASSED [ 50%]
tests/integration/test_owner_api_gateway.py::TestApiGateway::test_api_gateway_remove PASSED [100%]
================================= 2 passed in 26.14s ======================
(dip-data-vault)
With this happy feeling and result I can plan the next steps as there are a couple options. We could proceed and implement the other API Gateway and handler for data retrieval, or perhaps add authorization so the owner can only interact with the data that was provided before and not from somebody else, another option is to implement tokenization or encryption of data. That will be a question to mull over for the next post.