
his is the sixth post on information vault taken from John Crickett coding exercises. In this installment encryption for Private Data is added and also the retrieval of said data in plain text for when there is need for it. With this simple code it is almost unreasonable to have plaintext Private Data while using AWS DynamoDb, the downside is that full text search is not possible on these fields so a different approach is needed.
All the code can be found on.
https://github.com/mtzmontiel/dip-data-vault
To continue from previous posts which can be found here:

Now to add actual Private Data Storing with Encryption I’ll be using DynamoDb Encryption Client which uses AWS Key Management System as materials provider for encryption. First we need to define the Customer Managed Key that will be used, this is done on the serverless application model (SAM) Template as follows. Bear in mind that this will incur monthly costs of at least $1 USD/Month so be ready to discard the stack when you are done.
KmsKey:
Type: AWS::KMS::Key
Properties:
Description: Encryption key form Private Data Vault
Enabled: true
EnableKeyRotation: true
KeySpec: SYMMETRIC_DEFAULT
MultiRegion: false
KeyPolicy:
Version: 2012-10-17
Id: key-default-1
Statement:
- Sid: "Enable Root User Permissions"
Effect: Allow
Principal:
AWS: !Sub "arn:aws:iam::${AWS::AccountId}:root"
Action: "kms:*"
Resource: "*"
Then to be able to use this key we need to add a an IAM Role that can perform the operations with it; at this point I decided to move away from SAM Connectors as adding individual policies and connectors means that there are multiple ways to create IAM Resources and it is a good idea to be clear with intentions so the Role definition will have both KMS, DynamoDb and Cloudwatch permissions.
VaultLambdaRole:
Type: AWS::IAM::Role
Properties:
Description: String
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Principal:
Service:
- lambda.amazonaws.com
Action:
- 'sts:AssumeRole'
Policies:
- PolicyName: KMS
PolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Action:
- 'kms:Encrypt'
- 'kms:Decrypt'
- 'kms:GenerateDataKey*'
Resource: !GetAtt KmsKey.Arn
- PolicyName: DynamoDb
PolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Action:
- 'dynamodb:PutItem'
- 'dynamodb:UpdateItem'
- 'dynamodb:DeleteItem'
- 'dynamodb:DescribeTable'
- 'dynamodb:GetItem'
Resource: !GetAtt VaultTable.Arn
- PolicyName: Cloudwatch
PolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Action:
- 'logs:CreateLogGroup'
- 'logs:CreateLogStream'
- 'logs:PutLogEvents'
Resource: '*'
Then we add dependency and configure the DynamoDb encryption client. On requirements.txt this is appended.
dynamodb-encryption-sdk
And on the owner lambda we change it so it creates an Encrypted Table with default action of None and Sign and Encrypt action for enc_data attribute.
import boto3
import botocore
from dynamodb_encryption_sdk.material_providers import CryptographicMaterialsProvider
from dynamodb_encryption_sdk.encrypted.table import EncryptedTable
from dynamodb_encryption_sdk.structures import AttributeActions
from dynamodb_encryption_sdk.identifiers import CryptoAction
from dynamodb_encryption_sdk.material_providers.aws_kms import AwsKmsCryptographicMaterialsProvider
def create_table(table_name, key_id):
return create_secure_table(table_name, key_id)
def ddb():
return boto3.resource('dynamodb')
def create_table_without_encryption(table_name):
return ddb().Table(table_name)
def create_secure_table(table_name, key_id):
materials_provider = create_materials_provider(key_id)
return create_encrypted_table(table_name, materials_provider)
def create_materials_provider(key_id):
return AwsKmsCryptographicMaterialsProvider(key_id)
def create_encrypted_table(table_name, materials_provider):
table = boto3.resource('dynamodb').Table(table_name)
attribute_actions = AttributeActions(
default_action=CryptoAction.DO_NOTHING,
attribute_actions={
'enc_value': CryptoAction.ENCRYPT_AND_SIGN
}
)
return EncryptedTable(table, materials_provider, attribute_actions=attribute_actions)
And the store data function is changed to add the value which will end up encrypted.
def store_data(event, context):
"""Store Private data and respond with corresponding tokens"""
elements = extract_elements(event)
results = dict()
principal_id = extract_principal_id(event)
for k,v in elements.items():
token = tokenize(v)
ddresult = table.put_item(Item={
"pk": get_pk(principal_id, token),
"owned_by":principal_id,
"token": token,
"data_class": v["classification"],
"enc_value": v["value"]
})
if ddresult["ResponseMetadata"]["HTTPStatusCode"] != 200:
results[k] = dict()
results[k]["success"] = False
continue
results[k] = dict()
results[k]["token"] = token
results[k]["success"] = True
return results
Once we deploy and run the tests, the Private Data DynamoDB Table has these contents.
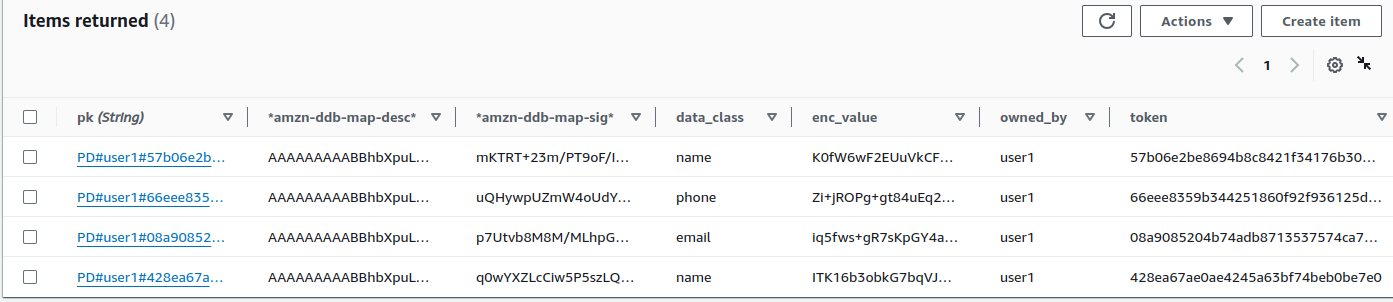
With this the remaining part is to return the plain text data which is done with the same Table object via a Get operation assembling the partition key from the owner and the token. This will be left off as the exercise has already been too long but the code is similar to this.
def get_data(event, context):
"""Get private data by tokens"""
principal_id = extract_principal_id(event)
results = dict()
token = extract_token(event)
results["token"] = token
try:
ddresult = table.get_item(Key={"pk": get_pk(principal_id, token)},
ConditionExpression="owned_by = :val",
ExpressionAttributeValues={":val": principal_id})
if ddresult["ResponseMetadata"]["HTTPStatusCode"] != 200:
results["success"] = False
results["message"] = "Could not process request."
else:
results["success"] = True
results["message"] = "Successfully Retrieved"
results["data"] = ddresult["Item"]["enc_data"]
results["data_class"] = ddresult["Item"]["data_class"]
except res.meta.client.exceptions.ConditionalCheckFailedException as e:
results["success"] = False
results["message"] = "Could not process request"
return results, e
return results, None