This will probably be a series of posts as it is not as simple as it seems.
A topic that has been recurring during my working life is a way to securely store information and make it available to the roles that actually have job requirements to use said information. John Crickett posted this on his coding challenges substack a couple of weeks ago.
https://codingchallenges.substack.com/p/coding-challenge-48-data-privacy
I quite like his approach and I’ve seen some variations of it being used in production at various places. Although I believe a little bit of context is missing as there might be many use cases for a privacy vault. One of them is storing Personal Identifiable Information (PII) where the User providing that information does not need to know there is a tokenization process in the underlying system as it would be really odd to see a token on the user interface instead of their name. On the other hand, printing a social security number which has regulations in place is a completely different matter, here a partial or truncated value might be acceptable on the user interface. The same would apply for a Credit Card number which the User stored on the system, the last 4 digits might be visible for a Card holder to be able to identify which card is being used. Which means depending on the type of data being stored the rules are quite different.
Also data stored in a vault is not only meant for end users but for other systems or operators. As in the examples above, a name might be shown on an Operator user interface to be able to interact with the client on a given workflow but not on others; for example a list of Users executing a certain task might be referred only by Client identification but some flows might require showing the real name of the Client either to be able to talk with them on phone or for reporting purposes where identification of individuals to an authority is necessary.
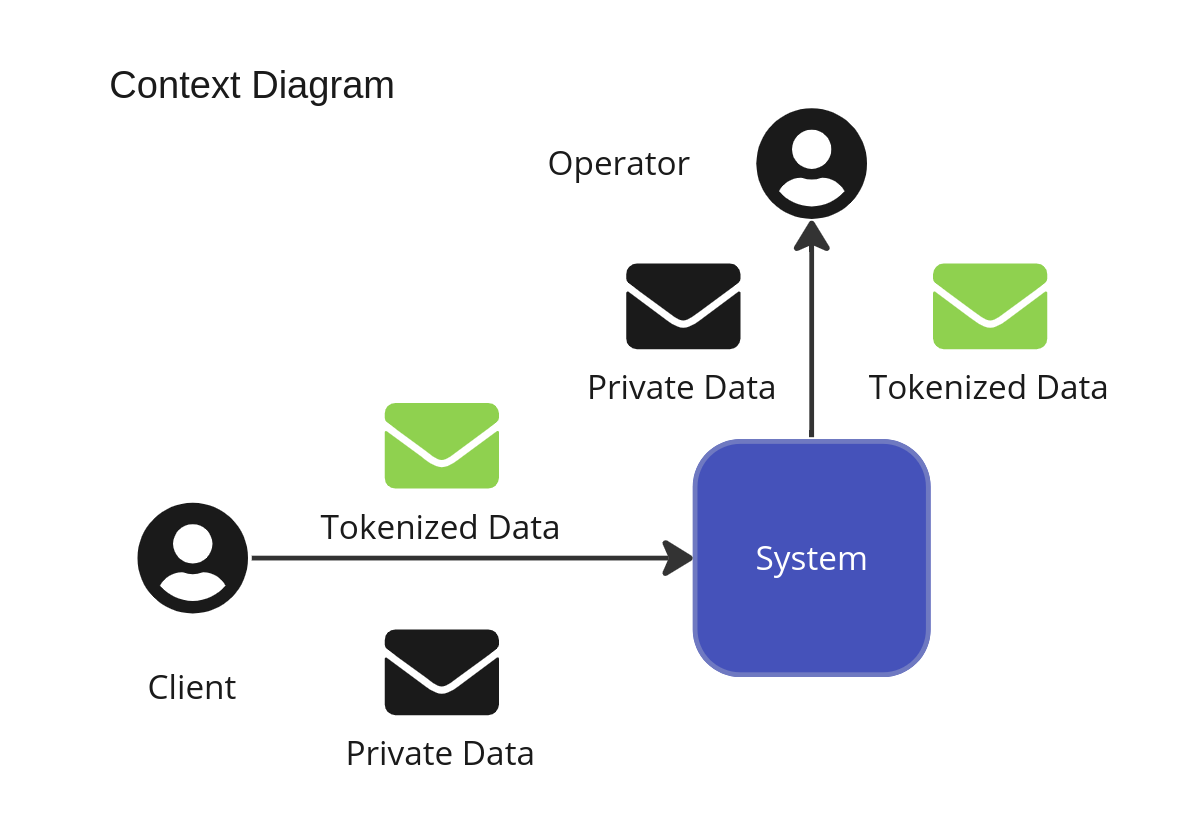
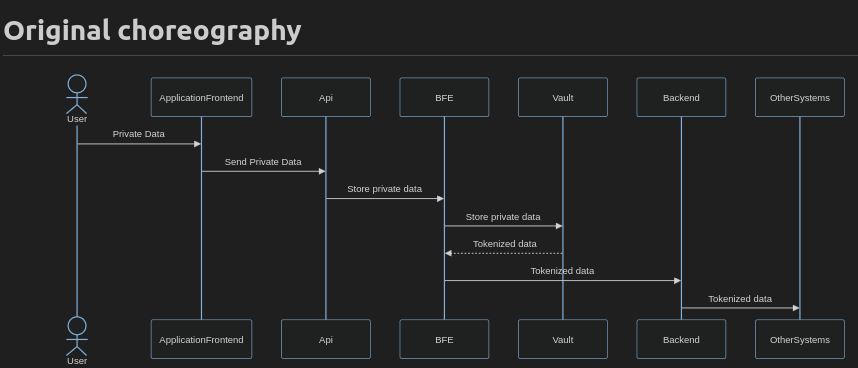
John uses the following diagram to set the context where an API Gateway uses a Backend for Frontend (BFE) which in turn sends the store request to the Data Privacy Vault. In essence the BFE orchestrates the operation and has visibility to the privacy information during the passthrough calls. In many data security frameworks it means that the API and the BFE are within scope of auditability.
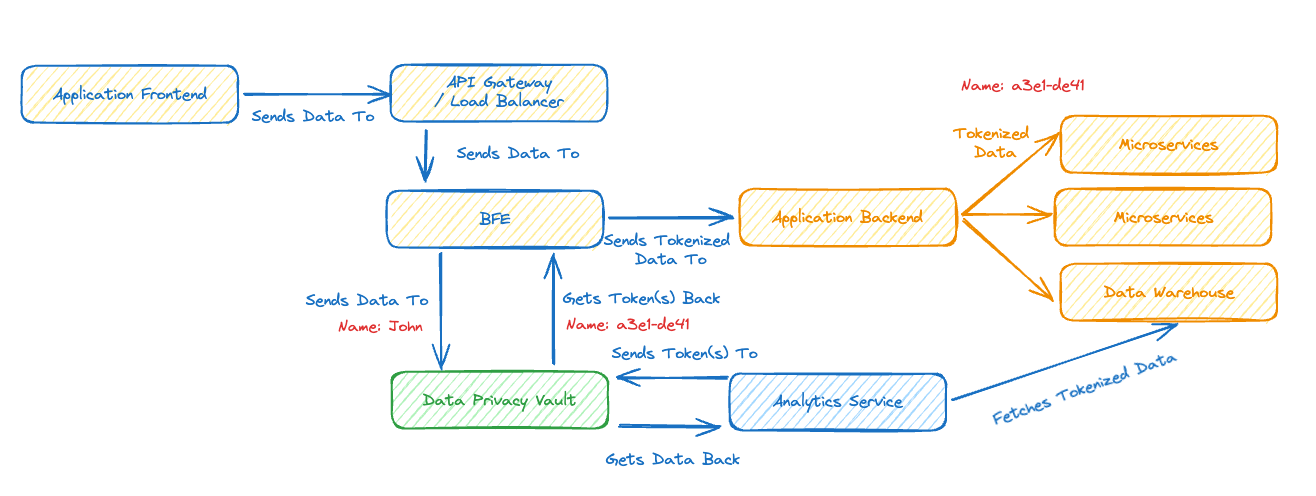
I wish to explore avoiding to force the BFE to pass along information, this means that the API Gateway must communicate with the vault directly and that the Application front end must deal with the tokens and more interactions with the backend.
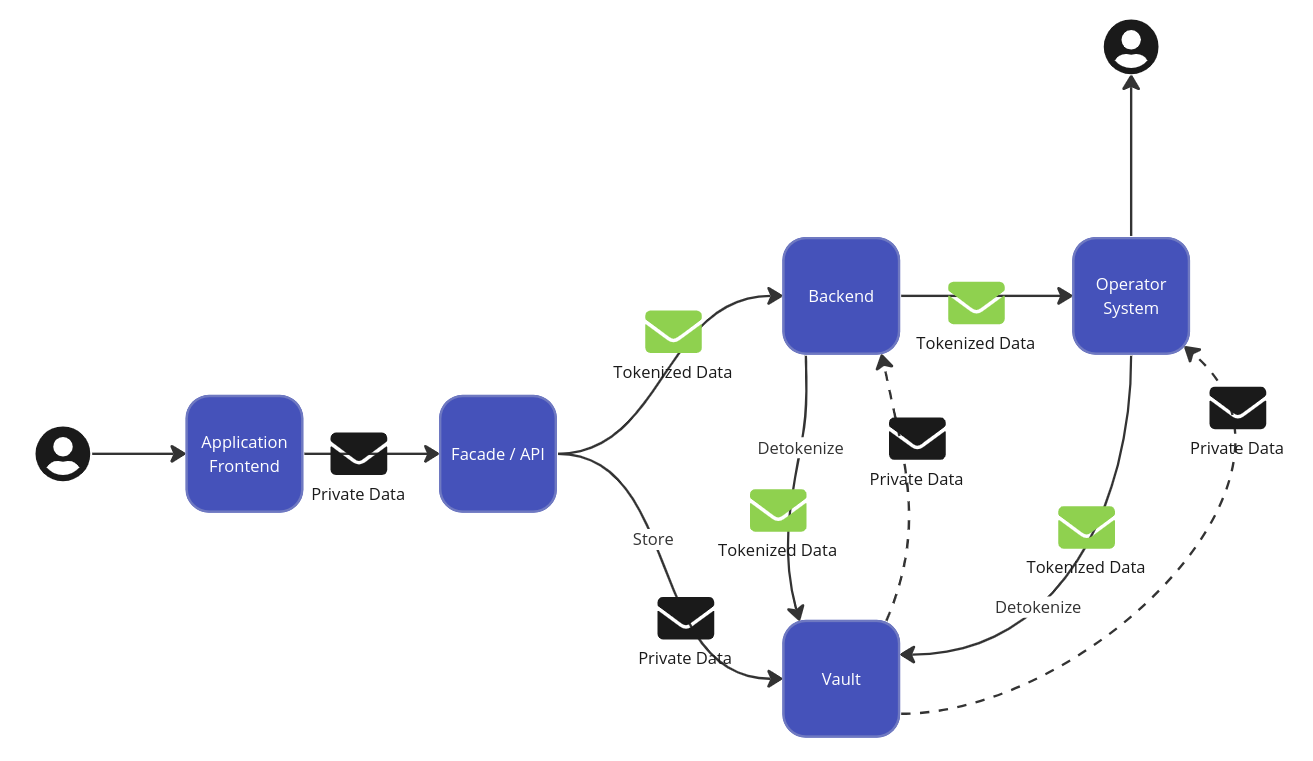
This particular change is difficult to represent on this kind of diagram, so on a sequence diagram both approaches would look like this. The first approach is choreographed by the BFE which gets the token from the vault.
While the second approach uses the Application Frontend to do choreography.
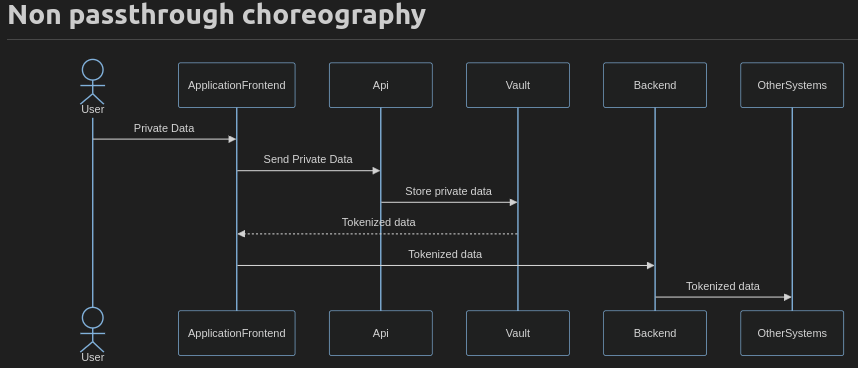
Here are some of the disadvantages of the second approach, firstly the leg between Application Frontend and API is expensive in terms of latency and more worrisome is that now Application Frontend has more responsibilities and could become a vector for attack later.
Let’s take a step back to figure out what is the use case for a vault with a specific data type instead of something generic. Building a generic application is a difficult task as the use cases and ways of implementing both client and server depend on what are the constraints and desired interactions.
During a flow a User needs to send Private Data to the system so it can be used later, for the moment the user does not need to retrieve back that information so let’s focus on the storage part. This means that the User has already started interacting with the system and should already be authenticated and within the flow and each interaction with the system has already something on each message that can be used to identify the user and thus associate all activities performed. Additionally the Private Data needs to be associated with that particular flow and user on the vault.
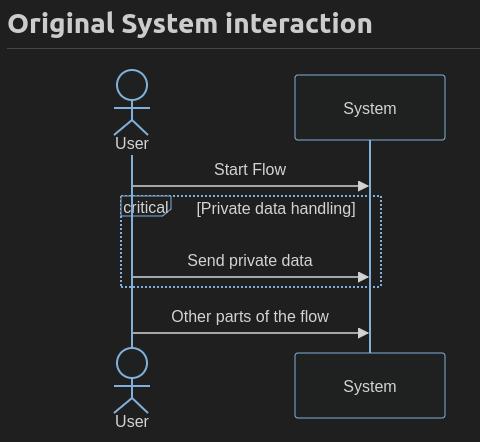
The most simple way of doing this is via Choreography with the first approach in which the BFE aggregates the flow information, user identification and tokens returned by vault. But if we want to avoid having BFE to have to be passing through Private data to Vault something needs to be different. Additionally having a component do flow choreography means that state needs to be handled by said choreographer and if an additional flow wants to also use the vault, also needs to change accordingly. So we might want to take a step back and see how private data is used.
Store Private Data and allow any principal to get the original value.
Store Private Data and allow only authorized principals to get the original value.
Store Private Data and allow Owner User and Authorized Principal to get the original value
Store Private Data and allow authorized principals involved in the Flow to get the original value
Store Private Data and forward to third party on expected flows
There are also other security concerns that we must take into consideration
Avoid abuse of Private Data storage (DDoS, Exfiltration)
Retention and Lifecycle
Audit log of utilization of Private Data
Audit log of acquiring of Private Data
Classification of Private Data
Ownership of Private Data
All of this adds complexity to the solution, so then for this particular exercise I want to tackle just a few of these concerns.
So to simplify this I’m going to focus solely on this use cases
Store Private Data for the Owner
Allow Private Data Owner to delete Private Data from the System thus disabling further use in the future.
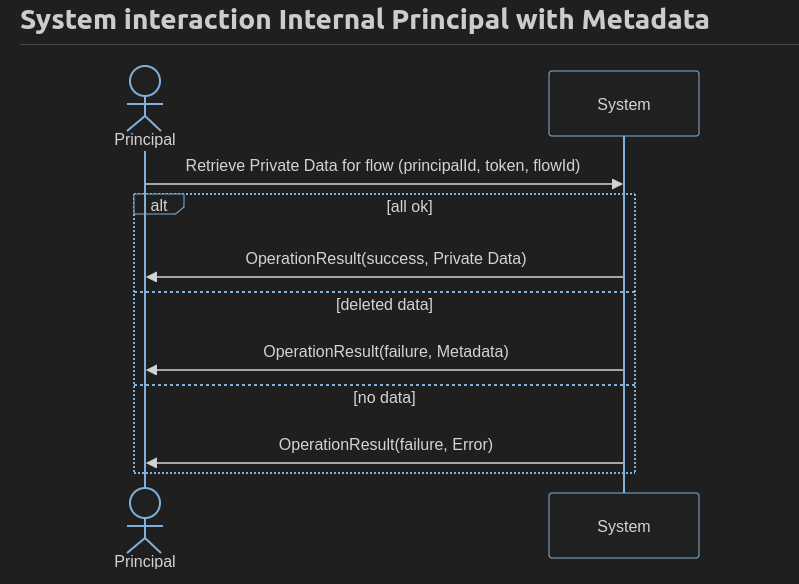
Allow only internal Principals to retrieve it for a particular flow
All interactions from internal Principals where Private Data is wanted but not available anymore should be able know that it was deleted, who was the Owner and when it was Deleted
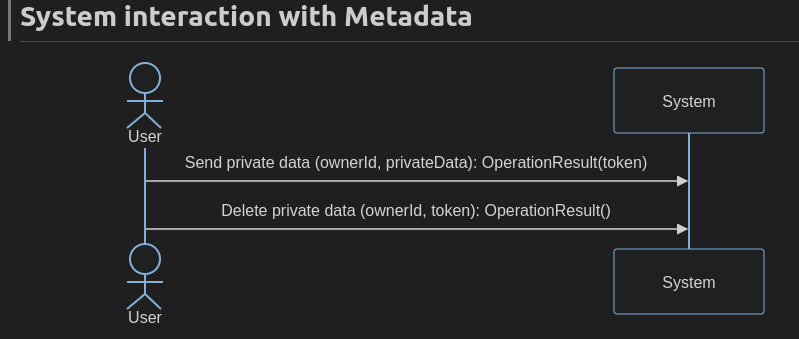
And for principal