

This is part 2 of a series Design in Public, in the prior post I did a drill down on the requirements that are interesting for me.
Store Private Data for the Owner
Allow Private Data Owner to delete Private Data from the System thus disabling further use in the future.
Allow only internal Principals to retrieve it for a particular flow
All interactions from internal Principals where Private Data is wanted but not available anymore should be able know that it was deleted, who was the Owner and when it was Deleted
To store private data there is normally more than one type of information that is stored, for example Addresses, emails, phone numbers, Full Names, Social Security Numbers, Card number (Primary Account Number), Expiry Date. The number of interactions with the system could be modeled as 1 interaction per Data element or to be able to send multiple data elements on a single interaction. Allowing the client to decide how to implement this is better in this scenario so it means that designing for multiple data elements on a single call but only sending one element is possible, therefore I’ll continue with this assumption.
Store multiple Private Data elements for the Owner
Classification of data as provided by Owner/Caller from a defined list: Full Name, Telephone, Email
At this point I’ll leave out of scope the following
Deduplication of Data Elements on a single request. Which means that if the same data element is provided multiple times, each one will be treated independently on the backend.
Validation of data types and data classification. Which means that if a value is sent no attempt to match it to expected data format will be made. This would not be acceptable on a production ready system but this exercise is meant to be as simple as possible.
To delete private data the owner must provide the token as it is the only public reference for private data therefore acting as an Identifier, this means that each token must be unique. Now the topic becomes interesting as any token now must have sufficient entropy to avoid collisions and depending on what is the structure of the tokens this might be difficult to implement and considerations for range of output values must be done.
For example Names are the simplest to handle as a string of more than 12 characters with spaces could be used, same as email but with a ‘@’ character in the middle and some ‘.’ or even GUIDs or ULIDs if the downsides of using both of them are acceptable.
Telephone numbers might be tricky as it only expects numeric characters except for the area code at the start of the value and considering that duplicated values will consume another token from the available values. Validate exhaustion of the token pool is important in this case. Perhaps reuse of deleted tokens can be considered later but this has implications on consumer systems.
To exchange a Token for the original Private Data the client must present the Token and the system must validate authorization to exchange said token. This is where delimiting the security boundaries of the system is paramount.
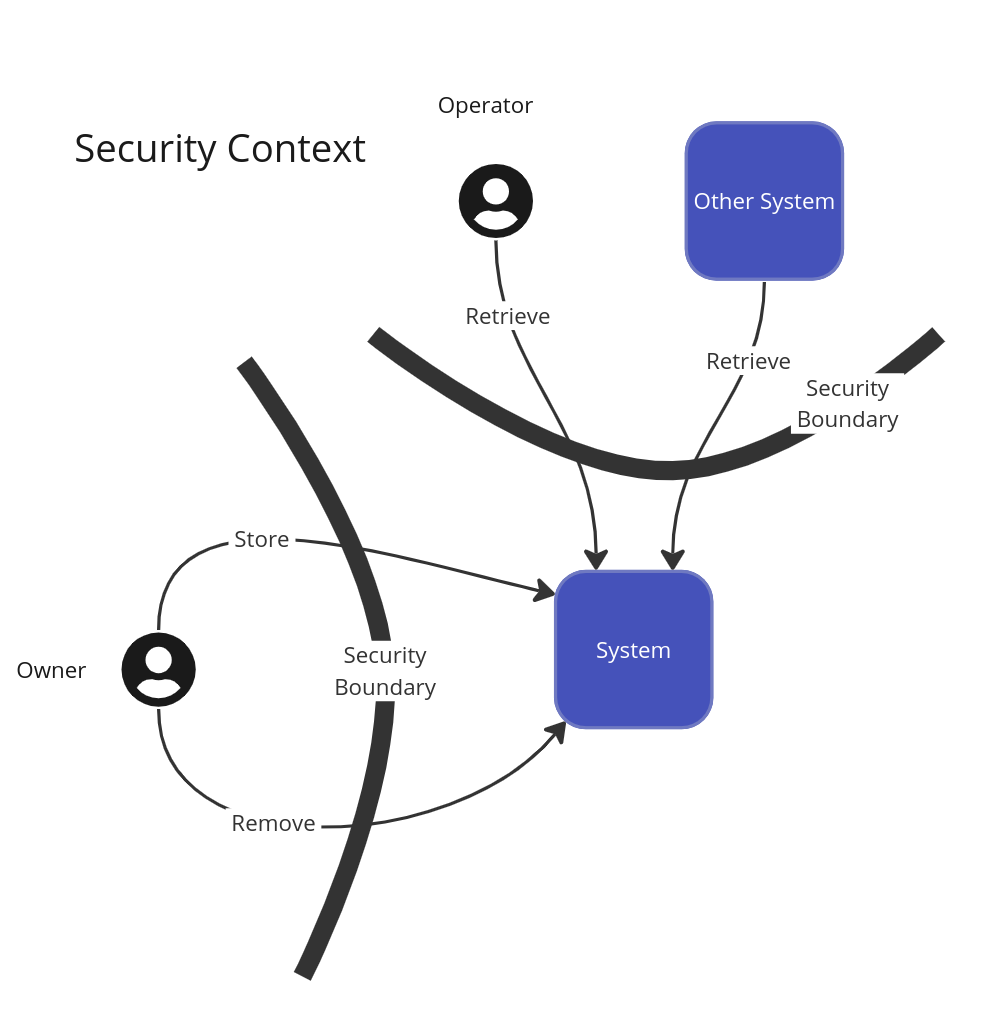
To keep things simple let’s assume that Owner always uses the same public interface while Operators and Other systems have a different interface. This topology allows the use of different user pools or principal sources hence dividing the actions to different interfaces completely. Then there is a need to correctly match each token with a Owner to allow deletion of Private Data. This allows partitioning at Owner Level which also allows to be pragmatic on the Retrieval endpoint and force clients to also provide an Identifier for Owner which might already be in use in other parts of the system. The other benefit of this approach is that the token pool now has expanded as it is partitioned by Owner. Let’s look at the data access patterns.
Store Private data for Owner
Delete Private Data for Owner by Token
Retrieve Private Data by Owner and Token